Module processing¶
Note
This chapter applies to builder engines that use Dockerfile as the input.
Understanding how modules are merged together is important. This knowledge will let you introduce modules that work better together and make rebuilds faster which is an important aspect of the image and module development.
Order is important¶
Installation order of modules is extremely important. Consider this example:
1modules:
2 repositories:
3 # Add local modules located next to the image descriptor
4 # These modules are specific to the image we build and are not meant
5 # to be shared
6 - path: modules
7
8 # Add a shared module repository located on GitHub. This repository
9 # can contain several modules.
10 - git:
11 url: https://github.com/cekit/example-common-module.git
12 ref: master
13
14 # Install selected modules (in order)
15 install:
16 - name: jdk8
17 - name: user
18 - name: tomcat
On lines 16-18 we have defined a list of modules to be installed. These are installed
in the order as they are defined (from top to bottom). This means that the first module installed
will be jdk8 followed by user and the tomcat module will be installed last.
The same order is used later in the module merge process too.
Note
Defining module repositories in the repositories section does not require any particular order.
Modules are investigated after all modules repositories are fetched.
Module processing in template¶
Each module descriptor marked to be installed can define many different things. All this metadata needs to be merged correctly into a single image, so that the resulting image is what we really expected.
This is where templates come into play. We use a template to generate the Dockerfile that is later fed into the builder engine.
This section will go through it and explain how we combine everything together in the template.
Note
Sections not defined in the module descriptor are simply skipped.
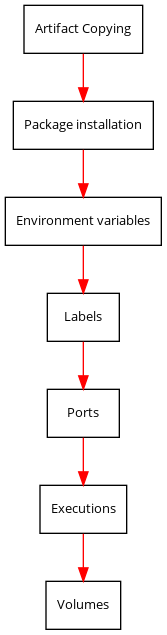
Artifacts¶
The first thing done for each module is the copying of any defined artifacts.
This is useful to ensure files are copied into the container. This can avoid needing an explicit script (triggered
by execute:) that copies the files. Instead the files can be listed:
artifacts:
- path: artifacts/maven.module
dest: /etc/dnf/modules.d`
Note
It is recommended to set the chmod/chown permissions correctly on the initial files so they are preserved upon copy.
Packages¶
Next is the package installation for all packages defined in the module. We do not clean the cache on each run, because this would slow subsequent package manager executions. You should also not worry about it taking too much space, because every image is squashed (depends on builder though).
Package installation is executed as root user.
Note
It is only possible to define a single package manager for an image (although multi-stage images may have different package managers). A package manager may be defined in a module or in an image (the latter takes precedence).
Environment variables¶
Each defined environment variable is added to the Dockerfile.
Note
Please note that you can define an environment variable without value. In such case, the environment will not be added to Dockerfile as it serves only an information purpose.
Labels¶
Similarly to environment variables, labels are added too.
Ports¶
All ports defined in the descriptor are exposed as well.
Executions¶
This is probably the most important section of each module. This is where the actual module installation is done.
Each script defined in the execute section is converted to a RUN instruction.
The user that executes the script can be modified with the user key.
Volumes¶
Last thing is to add the volume definitions.
Flattening nested modules¶
Above example assumed that modules defined in the image descriptor do not have any child modules. This is not always true. Each module can have dependency on other modules.
In this section we will answer the question: what is the order of modules in case where we have a hierarchy of modules requested to be installed?
Best idea to explain how module dependencies work is to look at some example. For simplicity, only the install section will be shown:
# Module A
name: "A"
modules:
# This module requires two additional modules: B and C
install:
- name: B
- name: C
# Module B
name: "B"
modules:
# This module requires one additional module: D
install:
- name: D
# Module C
# No other modules required
name: "C"
# Module D
# No other modules required
name: "D"
# Module E
# No other modules required
name: "E"
# Image descriptor
name: "example/modules"
version: "1.0"
modules:
repositories:
- path: "modules"
install:
- name: A
- name: E
To make it easier to understand, below is the module dependency diagram. Please note that this diagram does not tell you the order in which modules are installed, but only what modules are requested.
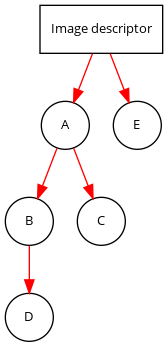
The order in which modules will be installed is:
D
B
C
A
E
How it was determined?
modules = []
We start with the first module defined: A. We find that it has some dependencies: modules B and C. This means that we need to investigate these modules first, because these need to be installed before module A can be installed.
We investigate module B. This module has one dependency: D, so we investigate it and we find that this module has no dependency. This means that we can install it first.
modules = ["D"]
Then we go one level back and we find that module B has no other requirements besides module D, so we can install it too.
modules = ["D", "B"]
We go one level back and we’re now investigating module C (a requirement of module A). Module C has no requirements, so we can install it.
modules = ["D", "B", "C"]
We go one level back. We find that module A dependencies are satisfied, so we can add module A too.
modules = ["D", "B", "C", "A"]
Last module is the module E, with no dependencies, we add it too.
modules = ["D", "B", "C", "A", "E"]
This is the final order in which modules will be installed.
Understanding the merge process¶
Now you know that we iterate over all modules defined to install and apply it one by one, but how
it influences the build process? It all depends on the Dockerfile instructions
that was used in the template. Some of them will overwrite previous values (CMD), some of them will just add
values (EXPOSE). Understanding how Dockerfiles work is important to make best usage of CEKit with
builder engines that require Dockerfile as the input.
Environment variables and labels can be redefined. If you define a value in some module, another module later in the sequence can change its effective value. This is a feature that can be used to redefine the value in subsequent modules.
Volumes and ports are just adding next values to the list.
Note
Please note that there is no way to actually remove a volume or port in subsequent modules. This is why it’s important to create modules that define only what is needed.
We suggest to not add any ports or volumes in the module descriptors leaving it to the image descriptor.
Package installation is not merged at all. Every module which has defined packages to install will be processed one-by-one and for each module a package manager will be executed to install requested packages.
Same approach applies to the execute section of each module. All defined will be executed in the requested order.